
I had an interesting thing happen a few months ago where a troll in a chat room decided for some reason to run my site through the W3C's Nu HTML Validator and apparently was grievously wounded by the validation errors it had—and furthermore, had a big concern with the overall bandwidth consumption of the site, with all its images and heavy pages.
Rather than simply solving the problem by not visiting my site, this person apparently felt some sort of imperative to berate me over these things and not. let. it. drop, making the chat room difficult to be in and necessitating action on my part.
So, rather than try to verbally wrangle with a troll, I whipped up a technological solution. And, of course, the monkey in my soul decided to have a little fun with it.
I. Lassoing the HTML Validator
Nowadays, if you run this site through the W3C's validator, you'll see a quite different result than you'd expect.
Doing this was pretty simple at first, but as my site grew and I implemented various forms of caching, it got more complicated.
First, I created a separate page on my domain, unlinked from any other pages. For opsec, I'm not going to reveal the actual URL, but for purposes of demonstration let's say it's https://michaelkupietz.com/validatorpage.html.
Now, the IP of the W3C HTML Validator is 52.22.66.203, and there's another one at validator.nu at 46.226.111.50, so at first, I just added this to the top of my WordPress child theme's header.php file:
$actual_link = "https://$_SERVER[HTTP_HOST]$_SERVER[REQUEST_URI]";
$w3ipArr = array('52.22.66.203','46.226.111.50');
if ((in_array(@$_SERVER['REMOTE_ADDR'], $w3ipArr) || in_array(@$_SERVER['HTTP_X_CLIENT_IP'], $w3ipArr) || in_array(@$_SERVER['HTTP_X_FORWARDED_FOR'], $w3ipArr)) && ||str_contains($actual_link,"showthepage") )
{
header("Location: http://michaelkupietz.com/validatorpage.html");
die();
}Now, there's an issue to consider: I actually do occasionally want to run my site through the validator. In the above code, I have allowed for this possibility by checking the URL for a specific URL parameter, in this case "showthepage". Now, I can run https://michaelkupietz.com?showthepage through the validator, and it will serve the original page, so I can see it. But anybody casually trying to check my page for purposes of hectoring me will instead see a... dissausive message.
It worked like a charm.
For a while.
Oh, no, it's CloudFlare
Now, not long after this, I stopped using quic.cloud as my CDN (because, I don't mind telling you, their support is absolutely terrible.) I moved over to a paid CloudFlare account, and activated their caching features for greater performance, without stopping to think that this would: A.) often serve pages from CloudFlare's external cache, preventing my site's logic that determines whether to serve the regular site or the validator-specific page from ever even seeing the request; and B.) Unknown to me at the time, changing the referring IP address I was checking in those $_SERVER[] header checks above, since CloudFlare gets the request for the page, rewrites it, and then sends it along to my server itself.
First we'll solve (B). This was pretty easily fixed with a minor code change. HTTP_CF_CONNECTING_IP is a header CloudFlare attaches to indicate the originating IP address of the request.
$actual_link = "https://$_SERVER[HTTP_HOST]$_SERVER[REQUEST_URI]";
function getClientIp() {
if (!empty($_SERVER['HTTP_CF_CONNECTING_IP'])) {
return $_SERVER['HTTP_CF_CONNECTING_IP'];
}
if (!empty($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$ips = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']);
return trim($ips[0]);
}
if (!empty($_SERVER['HTTP_X_REAL_IP'])) {
return $_SERVER['HTTP_X_REAL_IP'];
}
if (!empty($_SERVER['HTTP_X_CLIENT_IP'])) {
return $_SERVER['HTTP_X_CLIENT_IP'];
}
return $_SERVER['REMOTE_ADDR'] ?? '';
}
$remoteIP = getClientIp();
$w3ipArr = array('52.22.66.203','46.226.111.50');
if ( in_array($remoteIP,$w3ipArr) && !str_contains($actual_link,"mktest") )
{
header("Location: http://michaelkupietz.com/flipoff.html");
die();
}Ok, this means that, on the occasions when the request is sent to my server instead of handled entirely by CloudFlare's cache, my server can now see again when it's W3C's Validator asking for the page and serve up the right version.
Handling (A) was slightly tricker. This involves telling CloudFlare "For certain specific IP addresses, the pages need to be cached separately because they may be served different versions."
This requires setting up code on CloudFlare to handle this.
First try: the wrong way to do it (as recommended by AI)
Here's what I did first, for two weeks before I discovered problems with it, archived for general interest and insight into CloudFlare:
CloudFlare has what are called "workers" that are small functions that you can run on incoming requests and take programmatic actions on them.
Here's the step by step instructions I followed:
- Log into the Cloudflare dashboard
- Go to Workers & Pages in the left sidebar
- Click Create application
- Choose Create Worker
- Give it a name (like "ip-cache-router")
- Click Deploy to create a basic worker
- Then click Edit code to modify it
-
Delete the default code and paste this:
addEventListener('fetch', event => { event.respondWith(handleRequest(event.request)) }) async function handleRequest(request) { const clientIP = request.headers.get('CF-Connecting-IP') const specialIPs = ['192.168.1.100', '10.0.0.50'] // Replace with your actual IPs let cacheKey if (specialIPs.includes(clientIP)) { // Each special IP gets its own cache bucket cacheKey = request.url + '|ip:' + clientIP } else { // All normal users share one cache bucket cacheKey = request.url + '|normal' } const response = await fetch(request, { cf: { cacheKey: cacheKey } }) return response } - Click Save and deploy
- Test it by clicking Send in the test panel
- Go back to Workers & Pages
- Click on "ip-cache-router"
- Go to Settings tab → Triggers
- Click Add route
- Enter the domain pattern (e.g.,
michaelkupietz.com/*) - Select my zone
- Click Save
That's it! The worker now intercepts requests to my domain and create separate cache buckets for my special IPs vs everyone else. The route setup is the key step - that's what tells Cloudflare to run my worker for requests to your domain.
Update! How the above ruins your CloudFlare stats
True confession, I got the above worker code from Anthropic's FraudeClaude AI. Being AI, it of course didn't bother to tell me the side effects of doing things this way: CloudFlare stops tracking your cache stats.
I ended up disabling the above and just using cache rules to bypass the cache for certain IPs. Though the "expression builder" menu interface doesn't offer ip source as a filter, but you can manually enter something like (ip.src eq [IPv4 address #1]) or (ip.src eq IPv4 address #2]) or (ip.src eq IPv6 address]) or (ip.src eq 46.226.111.50)) and tell it Bypass cache to bypass caching for visitors for those IP addresses. This way when you check your cache stats, they're there.
Another Oversight
And then it turned out I'd made one more oversight.
A while before, unhappy with third-party caching options, I wrote my KTWP Page Cache WordPress plugin, which runs early in the loading process and checks if pages have changed before regenerating them. If they have, it stores them in a cache after generating them, and subsequently, until the next time they change, it just serves the generated result from the cache instead of regenerating the page every time someone requests it.
This plugin code is enabled by two simple lines at the bottom:
add_action('template_redirect', 'check_and_serve_cached_page', 1);
// This only runs if check_and_serve_cached_page() didn't find cached content
add_action('template_redirect', 'start_output_buffer', 2);So, even with all the logic I already added, sometimes, on the occasions when CloudFlare passed the requests through to the server, it was encountering my own caching plugin and still getting served a cached version prior to evaluating the originating IP address. So, we need another check to bypass this cache:
$dontCacheIP= array('52.22.66.203','46.226.111.50'); //IPs never to serve cached version to
function ktwp_pc_getClientIp() {
if (!empty($_SERVER['HTTP_CF_CONNECTING_IP'])) {
return $_SERVER['HTTP_CF_CONNECTING_IP'];
}
if (!empty($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$ips = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']);
return trim($ips[0]);
}
if (!empty($_SERVER['HTTP_X_REAL_IP'])) {
return $_SERVER['HTTP_X_REAL_IP'];
}
if (!empty($_SERVER['HTTP_X_CLIENT_IP'])) {
return $_SERVER['HTTP_X_CLIENT_IP'];
}
return $_SERVER['REMOTE_ADDR'] ?? '';
}
$remoteIP = ktwp_pc_getClientIp();
if ( !in_array($remoteIP,$dontCacheIP) )
{
// This hook runs very early, before WordPress starts building the page
add_action('template_redirect', 'check_and_serve_cached_page', 1);
// This only runs if check_and_serve_cached_page() didn't find cached content
add_action('template_redirect', 'start_output_buffer', 2);
}
Now, the hooks to activate the caching function don't even run if a request comes in from an address that needs a special version served.
Note at this point that this is a quick-and-dirty fix that crosses the line into bad programming. I am using the same function here that I used in my theme file, with the name changed from getClientIp() to ktwp_pc_getClientIp() to avoid a PHP error from declaring the same function twice. Really, either the plugin or the theme or both should be using PHP classes to keep functions in their own scope and avoid potential collisions, or, better, either the functions to check IP addresses should be called with a WordPress action, or, all this similar functionality should be in one place, such as all moved into the plugin. I will likely do this.
Anyway, now, anybody seeking to hector me by looking for W3C HTML Validator errors on my site will get a clear message.
Yet Another Tweak
After this had been running for a few months I realized there was one problem: because I was using an http header to redirect the browser location, the W3C Validator was showing the URL of the page I'm redirecting to:
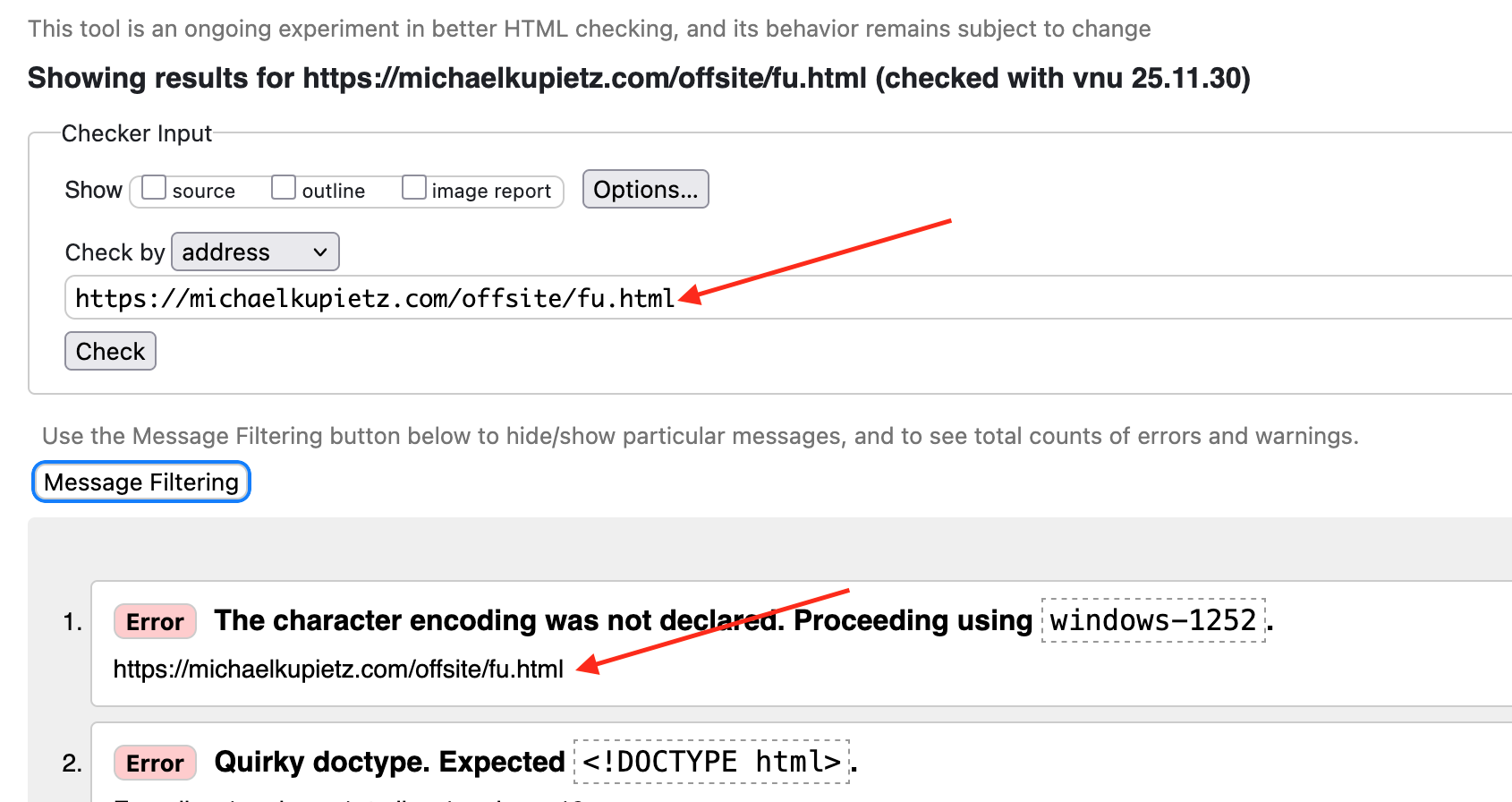
So, I added a PHP function to fetch the contents of that page and display it without redirecting:
function outputFileContents($filePath) {
// Check if file exists
if (!file_exists($filePath)) {
echo "Error: File not found - $filePath";
return false;
}
// Check if file is readable
if (!is_readable($filePath)) {
echo "Error: File is not readable - $filePath";
return false;
}
// Read and output file contents
echo file_get_contents($filePath);
return true;
}
Then I replaced header("Location: http://michaelkupietz.com/flipoff.html"); with outputFileContents('/home/kupietzc/domains/michaelkupietz.com/public_html/flipoff.html', and the final code was:
if ( in_array($remoteIP,$w3ipArr) && !str_contains($actual_link,"mktest") ) {
outputFileContents('/home/kupietzc/domains/michaelkupietz.com/public_html/flipoff.html');
die();
}Now, it doesn't give away the URL of the page it's actually serving, but rather, shows the URL the user tried to validate:
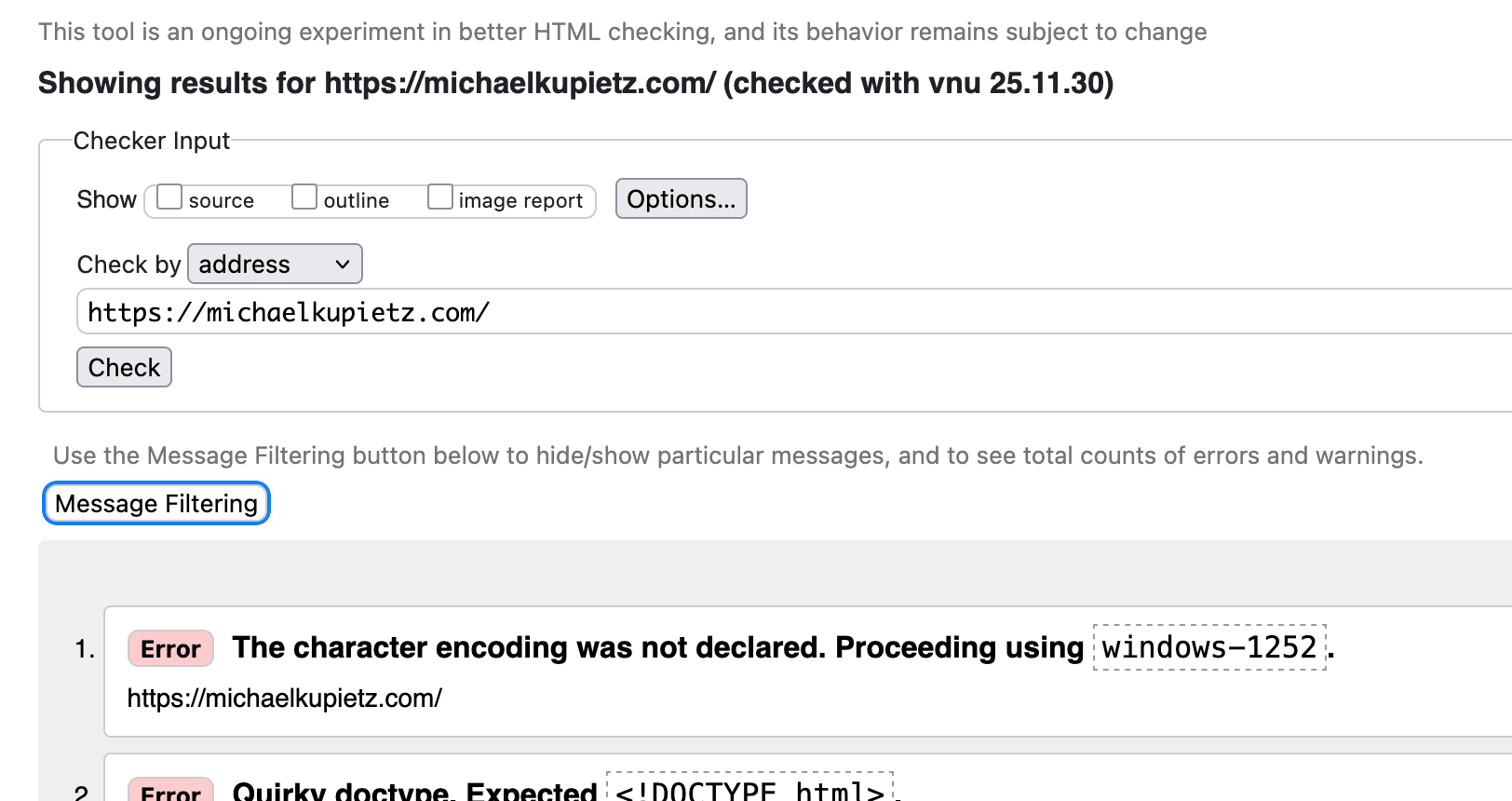
II. Functional Troll Repellent via Strategically Increasing Bandwidth
The other thing the troll hectored me about was my bandwidth. This site's front page is large and contains dozens of large images. This apparently was a big problem for this person.
Fortunately, this person had dropped some information that told me what part of the world they were in, and this enabled my to search my access logs for visits from that part of the world around the time they were bothering me and identify their IP address. This enabled me to serve up some customized features, just for them.
In this case I didn't want to use a whole separate page for them, because I wanted to retain my site's normal look and feel. I just wanted to give them a special greeting... and a special gift.
So, I added the following to the top of my child theme's header.php file, below the code that handles visits from the W3C validator, within my template's HTML <head> tag output, and using the same $actual_link and $remoteIP variables I defined earlier:
$blockUserIp= array('[0.1.2.3]'); //troll IP address goes here
if ( in_array($remoteIP,$blockUserIp) ||str_contains($actual_link,"mktest") )
{
$blockTheUser=true; ?>
<link rel="preload" href="https://dumps.wikimedia.org/wikidatawiki/20241101/wikidatawiki-20241101-pages-articles-multistream.xml.bz2" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://dumps.wikimedia.org/wikidatawiki/20241001/wikidatawiki-20241001-pages-articles-multistream.xml.bz2" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://dumps.wikimedia.org/wikidatawiki/20240901/wikidatawiki-20240901-pages-articles-multistream.xml.bz2" as="fetch" type="application/octet-stream">
<link rel="preload" href="http://mattmahoney.net/dc/enwik9.zip" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://github.com/id-Software/DOOM/archive/refs/heads/master.zip" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://archive.org/download/doom3spa/DOOM3_1.iso" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://archive.org/download/doom3spa/DOOM3_2.iso" as="fetch" type="application/octet-stream">
<link rel="preload" href="https://archive.org/download/doom3spa/DOOM3_2.iso" as="fetch" type="application/octet-stream">
<?php
} else {$blockTheUser=false;}
Now, this does two things:
1. Sets a variable $blockTheUser=false which says if this visit is from the offending IP address or not.
2. Begins automatically downloading three months of full backups of Wikipedia in the background, plus the open source release of Doom, and all three disks of Doom 3, to the user's browser.
Now, I want to be clear: this would be highly immoral to secretly do to someone, even a troll, without telling them. Do not do things like this to unwitting users, ever.
However, that's why I set the variable. Further on in the template, below my theme's <body> tag and my site header and menu section, I added this:
<?php
if( $blockTheUser==true ) { ?>
<div style="width:40vw;position:fixed;display:block;top:120px;left:12px;background:#fff;z-index:999999;border:1px solid red;padding:12px;box-shadow:5px 5px 5px rgba(0,0,0,.25);">
Thank you for visiting my new, more user-friendly site implementation!<p> As a courtesy, this site is now stress-testing your browser by downloading and caching three months of complete dumps of Wikipedia's database in the background. To confirm this and see the results when it's finished, open your browser Inspector, check the Network tab, and reload the page.<p>
No need to thank me, I just like to help out.
</p>
<p>
Oh, also, just for your convenience, it's also downloading the open-source release of Doom.</p>
<p style="font-size:.7em">And all 3 disks of Doom 3.
</p>
</div>
<?php
}
?>
Then all that remained was to add the troll's IP address to the IP address array variables in my page caching plugin and my cloudflare worker, so requests from that address would go straight through without reading the page from the cache, too.
Now, with the user fully-informed, there has been no moral breach, but the troll has been thoroughly disincentivized from visiting my site or running it through the W3C HTML Validator.




